
In my previous post Game Over for VMs, what’s next? I made the case that the underlying concerns that gave rise to virtual machine technology no longer exist. Container technologies such as Docker have made all VMs, including the Java VM, unnecessary. This post documents an experiment defining the cost of using VM technologies for a specific and non-trivial use case.
Experimental Design
Design principles:
- A non-trivial use case with real world applications.
- Terabytes or even petabytes of data readily available for testing.
- A reputable third party has developed and open sourced functionally identical code which runs in both a native and a VM environment.
The design I settled upon was to test regex processing using Google’s RE2 library against the Common Crawl data set. Google has open sourced RE2 in both it’s C and Java forms.
Results
I developed a code base to extract potential phone numbers from the raw text format provided by Common Crawl written in both C and Java. The goal was to extract anything that looked like a phone number from the crawl data and provide the original matching line along with a standardized phone number as output. The intention was to use this program as a high performance upstream filter to “boil the ocean” and provide every potential instance of a phone number. Later downstream processing could then be used to validate and identify if the phone numbers were valid and actual, but it was not the intention of this process to do so.
The following command was used to execute the C test:
cat ~/Downloads/CC-MAIN-20160524002110-00000-ip-10-185-217-139.ec2.internal.warc.wet | time ./getphone-c/Release/getphone-c > getphone-c.txt
The following command was used to execute the Java test:
cat ~/Downloads/CC-MAIN-20160524002110-00000-ip-10-185-217-139.ec2.internal.warc.wet | time java -jar getphone-java/target/getphone-main.jar > getphone-java.txt
Both tests were executed on an uncompressed 412 MiB crawl file with an identical preceding warmup test. Both tests saturated a single core throughout the test.

| Environment | Throughput (Mib/sec) | Memory (KiB) |
|---|---|---|
| native | 380.6 | 714 |
| VM | 20.4 | 65536 |
| % savings | 94.6% | 98.9% |
Conclusions
This test assumes that Google puts reasonable effort into tuning both the C and Java versions of RE2. The test shows that for this use case the native implementation produces 20 times the hardware ROI of the VM implementation.






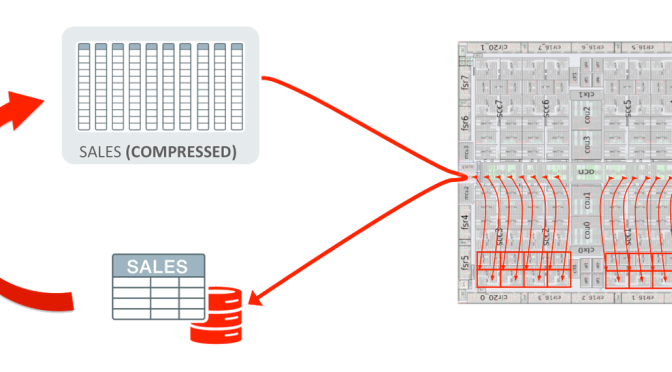
 Natively accelerated common analytic functions usable in C, Python, and Java have already shown a 6x lift for a
Natively accelerated common analytic functions usable in C, Python, and Java have already shown a 6x lift for a 


 Apache Arrow was announced today as a top level Apache project, promising to bring the performance of Apache Drill to the rest of the big data ecosystem. The good news is, if you are using Drill currently you are already using the gold standard in open source OLAP performance.
Apache Arrow was announced today as a top level Apache project, promising to bring the performance of Apache Drill to the rest of the big data ecosystem. The good news is, if you are using Drill currently you are already using the gold standard in open source OLAP performance.
 To me this weekend wasn’t the Panthers vs. Broncos match-up for Super Bowl 50, or when we found out that Bernie Sanders won the New Hampshire primary. Although both of these were hoooge: it WAS when these parallel but significant facts emerged:
To me this weekend wasn’t the Panthers vs. Broncos match-up for Super Bowl 50, or when we found out that Bernie Sanders won the New Hampshire primary. Although both of these were hoooge: it WAS when these parallel but significant facts emerged:

